近日,电子信息学院在计算机视觉与人工智能领域取得新进展,首次以上海电机学院为第一单位录用CCF-A类会议成果。其中,励雪巍等人的成果“REL-SF4PASS: Panoramic Semantic Segmentation with REL Depth Representation and Spherical Fusion”被CVPR 2026 (CCF A类国际会议,谷歌学术热门出版物排名第二,仅次于Nature)录用;张硕等人的成果“SimpleDiffusion: A Lightweight and Efficient Conditional Diffusion Model for Multi-Modal Salient Object Detection”被AAAI 2026 (CCF A类国际会议)录用。同时,学院培养了以人工智能2022级本科生鲍星含为代表的一批深耕人工智能前沿的学生,并探索与中电科联海创智等领域内企业的合作。
“REL-SF4PASS: Panoramic Semantic Segmentation with REL Depth Representation and Spherical Fusion”由励雪巍副教授为第一作者、电子信息学院人工智能2022级本科生鲍星含为学生第一作者、陈志敏教授为第三作者,主要聚焦全景语义分割(Panoramic Semantic Segmentation)领域。准确的全景语义分割是自动驾驶和虚拟现实等应用中的关键技术,对实现自动驾驶中的全向感知、增强现实和虚拟现实设备中的沉浸式体验有重大作用。现有方法对深度信息的处理往往直接套用经典的HHA深度表示,存在未能充分利用全景图像独特的球面几何特性、依赖相机参数、对场景中物体的表面法向量建模不足等局限。针对这些问题,本研究提出了基于REL深度表示和球面融合的新全景语义分割框架REL-SF4PASS。
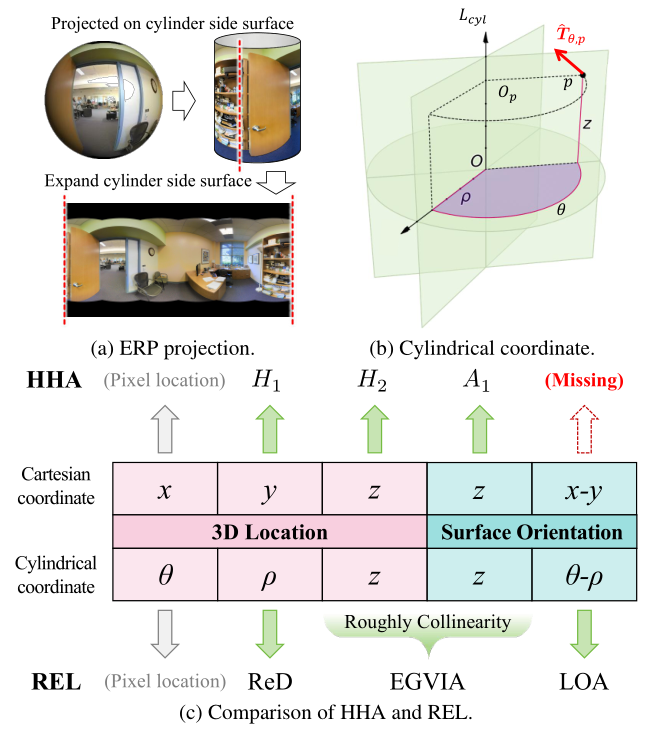
REL与HHA两种深度表示的对比
首先,基于柱坐标系提出了不依赖相机参数的REL深度表示,REL包含:表示平面距离的矫正深度(Rectified Depth, ReD)、融合了高度信息与表面法向量与重力方向的夹角的高程增益垂直倾角(Elevation-Gained Vertical Inclination Angle, EGVIA)以及建模表面法向量与圆柱切线之间的夹角的侧面取向角(Lateral Orientation Angle, LOA)。
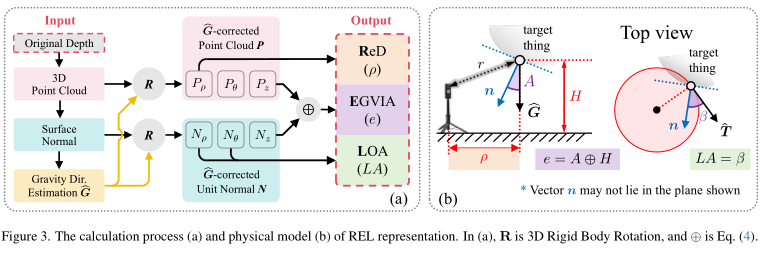
REL深度表示详细计算方法
其次,提出了球面动态多模态融合,采用基于球面的patch级MoE融合策略。通过在圆柱侧面上进行重叠的patch采样,并利用门控网络为不同patch选择最佳融合方式。
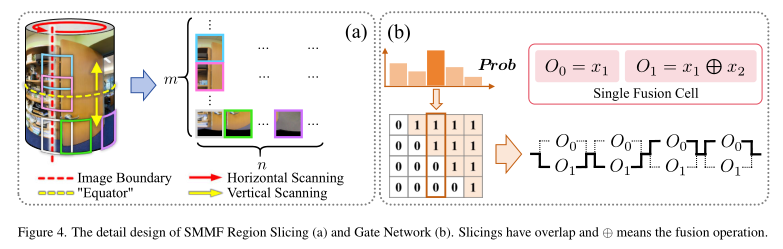
球面动态多模态融合示意图
在主流的Stanford2D3D Panoramic数据集上,本方法3 Fold平均mIoU提升了2.35%。在面对三维扰动时,性能方差降低了约70%,表现出极强的稳定性。本研究相关实验得到到了上海电机学院高性能计算平台的支持。
“SimpleDiffusion: A Lightweight and Efficient Conditional Diffusion Model for Multi-Modal Salient Object Detection”由张硕老师为第一作者,主要聚焦多模态显著目标检测(Multi-Modal Salient Object Detection, MSOD)领域。 多模态显著目标检测能够有效提升复杂场景下的显著目标定位能力,对医疗成像、机器人视觉和监控系统等实际应用具有重要意义。现有基于扩散模型的方法将MSOD视为由显著性特征引导的条件掩码生成过程,但常常忽略了Stable Diffusion的高计算成本和大尺度架构,导致与实际MSOD应用的不匹配。针对这些问题,本研究提出了首个不依赖Stable Diffusion的轻量化高效条件扩散模型SimpleDiffusion。
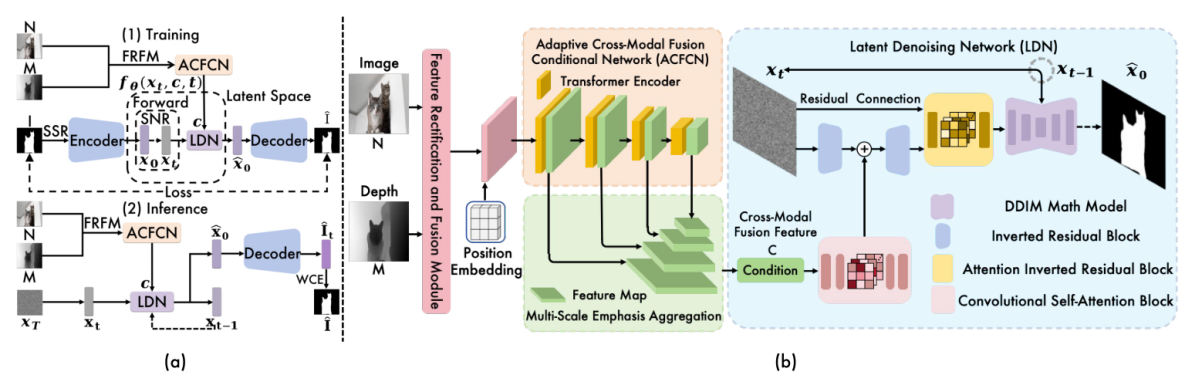
SimpleDiffusion示意图
首先,自适应跨模态融合条件网络(ACFCN)通过引入跨模态引导功能来增强条件表达能力,而该特征是分割具有详细边界的显著目标的关键。其次,为训练和采样阶段设计了定制的学习调度和输出策略,包括信噪比驱动方差自适应(SVA)、稀疏结构重组(SSR)和加权置信集成(WCE)等。上述组件和策略与潜空间去噪网络(LDN)结合,能够充分利用扩散模型的优势,同时显著提升计算效率并减少参数空间需求。
在多个MSOD 数据集上进行的实验表明,SimpleDiffusion与其他基于扩散模型的方法相比,将模型规模缩小了十倍以上,推理速度提升了五倍以上,且有相似甚至更优的性能。(供稿:电子信息学院)
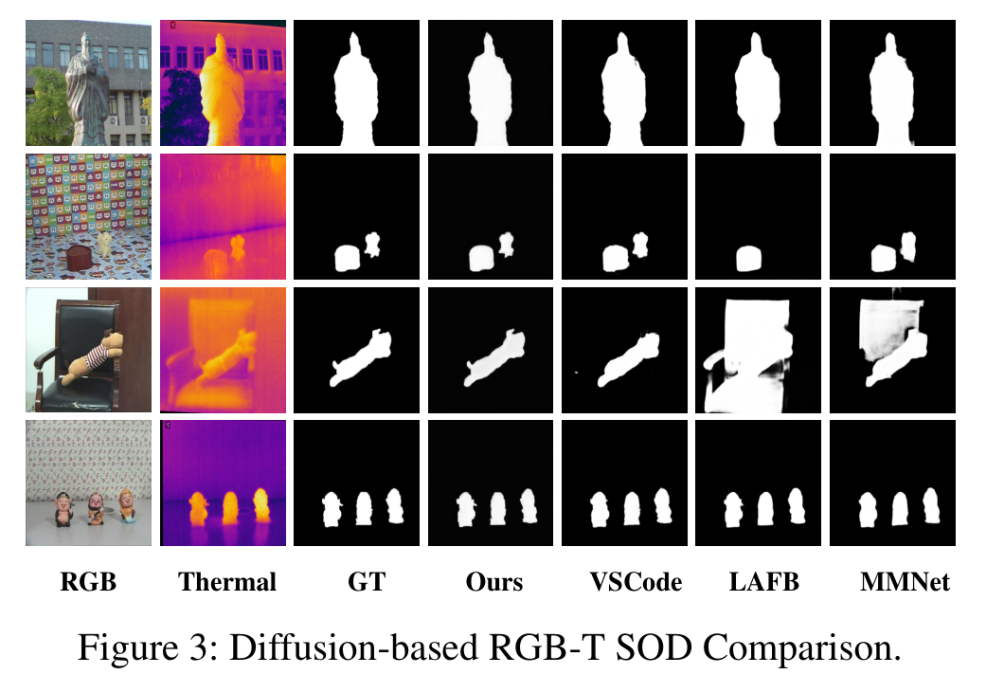
SimpleDiffusion可视化结果
相关录用证明(左)AAAI;(右)CVPR




